 DOI:
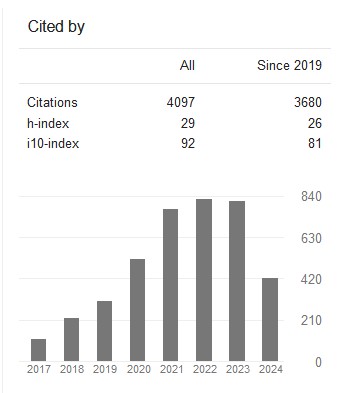
DOI: Google Scholar Analysis
For Authors






ijaems Issue
Analysis & Implementation of Clustering Data Mining Technique - An Approach to Efficient K-means Algorithm( Vol-2,Issue-9,September - September 2016 ) |
|
Author(s): Mr. Vilas Mahatme, Ms. Shital Radke |
Download Full Text PDF
Total View : 1822
Downloads : 167
Page No: 1546-1548
|
Keywords: |
|
|
clustering, data analysis, k means, initial seed. |
|
Abstract: |
|
|
Thousands of techniques are emerging for collecting scientific and real life data on a large scale. The traditional database queering system is available to extract required information. Clustering is one of the important data analysis techniques in data mining. K means are mostly used for many applications. While using basic k means algorithm one may face difficulties in optimizing the results as it is computationally expensive in the terms of iterations. The result of k means is based on selection of initial seed and total number of clusters which depends on the data set. As K means gives variety of results in each run, there is no any thumb rule available for selection of initial seed and the number of clusters. This paper includes approaches to improve the efficiency of k means is mentioned, which provides a better way of selecting the value of k. This approach will result in better clustering with reduced complexity. |
|
Cite This Article: |
|
|
Citations:
APA | ACM | Chicago | Harvard | IEEE | MLA | Vancouver | Bibtex
| |
Share: |
|




















